Как выглядит красивый HTML-код
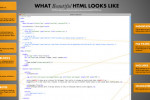
Крис Койер (Chris Coyier), автор CSS-Tricks, опубликовал замечательную схему того, как, по его мнению, должен выглядеть красивый и современный HTML-код. В своей статье он показывает пример, который представлен в трех вариантах: PNG-скриншот; оригинал в PSD-формате; текстовый вариант. Ниже я хочу привести свой свободный перевод комментариев ...

Комментарии (58)
Статья отличная. В оригинале ещё посмотрел. Спасибо за перевод.
Free From Styling (независимость от стилей) я думаю значит, не использовать inline styling. Весь стайлинг только в .css файле.
Я думаю, тут имеется ввиду, что даже если отключить CSS, сайт должен нормально восприниматься, а не разваливаться на части.
А я всегда именно так и делал, за исключением 12го пункта. А по поводу 21го тут ведь все понятно, имеется ввиду чтобы контент был доступен даже при отключенном CSS
Ну и в каких случаях при отключенном CSS могло бы потеряться важное содержимое документа? :)
лехко… сходу могу придумать — навигация прорисовывается бэкграундом…
По 20-му пункту: если использовать юникод, в ХТМЛ-мнемониках (HTML entities) становятся ненужными.
Я хоть и использую всегда UTF-8, по привычке указываю мнемоники.
Я всегда использую мнемоники, по-моему выглядит на много чище, чем просто вставлять определенный символ.
«Независим от Стилей» — это практически лозунг «Дня без CSS».
Смысл в том, что все оформление должно быть вынесено отдельно — HTML — язык описания данных, а не их оформления.
С практической точки зрения он говорит, что использовать inline style конечно допустимо, но не нужно.
В остальном — это хороший задел для тех, кто только начинает — остальным, уже «набившим руку» и пишущим HTML от этой самой руки (не знаю, как вы — я пишу от руки), наверное уже не очень нужно…
Ясно теперь с этим пунктом, спасибо за разъяснение.
Вообще-то аналогично, иначе я бы вряд ли писал статьи о верстке =)
Могу посоветовать вот такое решение: Conditional CAPTCHA for WordPress. Устанавливается в паре с Akismet’ом и если последний думает, что комментарий — спам, то просит комментатора ввести капчу.
Все новое — необходимо проверять и тестировать, иначе умрет прежде чем родится…
Dimox все очень просто — ставь графическую КАПЧУ
и еще «Я не робот», только переписать «Я согласен с правилами комментирования»
Вот и все — решена проблема со СПАМОМ — я уже так успешно отсеиваю их.
и нормальные комменты проходят и люди соглашаются еще с правилами…
Баба Яга против.
Спам — проблема владельца сайта, не надо вовлекать в эту борьбу посетителей.
Графическая капча уже не проблемма. А на счёт согласен с правилами комментирования пока думаю актуально.
Я вообще сделал обязательную регистрацию на блоге. правда комментируют мало, но зато расписывают как надо)
Спасибо большое, нашел для себя несколько новых пунктов, которые теперь постараюсь выполнять. :)
спасибо за интересную статью, я например css раньше делал как положено, но сейчас видно и хтмл буду
Спасибо, Дим! Как всегда шикарная и выверенная статья. А главное — полезная :)
Спасибо, Андрей, за, как всегда, замечательный позитивный комментарий =)
Не совсем понял пункт № 16. Чем класс col гораздо лучше, чем left?
P. S. Что-то мои данные не запоминаются — каждый раз заново ввожу.
Полагаю, приведен просто неудачный пример.
Речь идет о том, чтобы классам давать семантичные имена (ага, гляньте в код GMail)
Например, у меня есть несколько классов изображений — и названия у них семантичные в том смысле, что отображают смысл данного класса.
Пример — (достаточно) стандартные классы
.clearfloat{}
.alignleft{} .alignright{}
То есть по классу понятно, что он делает
Либо .post, .article, .content - понятно, да?
Спасибо, теперь понятно. Думаю у гугла классов так много, что все их семантичными сделать проблематично. Только если писать, что-нибудь вроде. alignleftsidebartopnoborder :)
Ну, так на всякий случай…
Классы же можно складывать, да?
например… class="post alignleft noborder by-author boldheader first"
col— это сокращение отcolumn(столбец).Это потому что я поставил скрипт кэширования страниц.
All due respect, а что, уже надо?
Я про кеширование…
Больше тысячи запросов в минуту бывает?
Дело не в количестве запросов, а в нагрузке, которую дают WordPress-сайты на сервер. К тому же это повлияло и на скорость. С кэшированием скорость загрузки блога увеличилась примерно в 20 раз, без него страницы открываются очень долго (такой хостинг).
Так это…
Удобство пользователей принесено в жертву.
А если блог стал загружаться быстрее в 20 раз, так это надо код чистить и смотреть, где возникают тонкие места.
Мой опыт говорит, что чаще всего термозит выдачу страницы Директ — возможно ли тут такая ситуация?
Впрочем, это уже офтоп
Три поля заполнить не так и сложно.
Нет, Директ тут ни при чем. Во-первых, WordPress сам по себе генерирует страницу долго, во-вторых, еще и хостинг тормозной, долго соединяется с БД. Вот тебе и узкие места. Вообще, весь WordPress — одно большое узкое место =)
В среднем, полминуты.
Это 30. На 10 комментариях — это 5 минут, между прочим. А ведь надо еще и работу работать!
Удобство клиентов — в первую очередь!
Выполняю многие рекомендации, но с некоторыми можно и поспорить. К сожалению, «красивость» кода — вещь очень относительная, тем более, что львиная доля этих красивостей погибнет при установке макета на CMS.
HTML5 — это конечно хорошо, но это ещё не стандарт. Поэтому пишу на «старом добром» XHTML 1.0 Strict.
Добавлять идентификаторы к body на самом деле не такая уж хорошая затея. Классы работают быстрее и их можно наставить несколько для одной и той же страницы. Вообще говоря, этот момент лучше просчитать перед началом вёрстки, посоветовавшись с программистом и здравым смыслом (где-то читал статью по этому поводу, если наткнусь, дам ссылку).
Подключение фреймворков с Google тоже не очень хорошо. Во-первых гугл иногда тоже может не работать, а во-вторых, внешние скрипты могут быть просто заблокированы (как у меня сейчас, из-за чего в этом блоге не работают, например, «табы» в сайдбаре).
Блокированы кем и зачем?
Внешние скрипты часто используются для показа рекламы, поэтому их и блокируют. Для блокирования используются User JS, такие как Block external scripts.
Подключение фреймворков с Гугла — это распространенная в Интернете практика. И то, что вы блокируете внешние скрипты, вовсе не значит, что такой способ подключения плох.
Он не плох, просто может не всегда работать ;) Поэтому я его и не использую.
Я ни разу не сталкивался с таким случаем, чтоб не работало. Сервера Гугла очень стабильны.
Для русскоязычного сайта лучше подключать jQuery с Яндекса:
js.static.yandex.net/jquery/1.3.2/_jquery.js
Почему? Во-первых у этого варианта намного больше шансов оказаться в кэше российского пользователя (jQuery подрубается уже на главной странице www.yandex.ru), возможное исключение — если аудитория сайта исключительно гиковская; во-вторых сервера Google находятся за рубежом, соответственно большой пинг, а значит и бОльшее время скачивания библиотеки; в-третьих у Яндекса договорённости с большинством провайдеров о локальном трафике, а значит библиотека скачается с максимальной скоростью (моя Yota, например, с народа качает с сумасшедшей скоростью).
Вывод: в подавляющем большинстве случаев гораздо лучше подключать jQuery с Яндекса.
И ещё у первоисточника мета-тег кодировки указан не по правилам HTML5. У первоисточника:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8″ />По правилам HTML5:
<meta charset="UTF-8″ />Да, действительно. Я почему-то не обратил на это внимание.
Ага! А когда я написал про HTML5, ты от него отбрыкивался, якобы ещё не готова технология :)
Кстати, не могу согласиться с тем, что дополнительные стили для устаревших браузеров — это красиво. Вынужденный костыль, от которого можно вообще избавиться для многих сайтов.
Кроме того уж слишком категоричное утверждение о том, что jQuery якобы самый красивый фреймворк. Один из самых толстых — может быть. Не понимаю, какая уж особая красота в подключении дофига кб дополнительного и чаще всего не нужного кода.
Какая связь путей к изображениям в HTML с RSS опять же непонятно зачем написано, ерунда какая-то.
Про классы с идентификаторами вообще тавтология получилась в контексте валидности. HTML с двумя одинаковыми идентификаторами не пройдёт валидацию.
19 пункт… это что вообще? 8-о «элементы, которые должны быть динамическими, являются динамическими». Вот это да!
Далее, 20 пункт. Characters Encoded — зачем? В UTF-8 спокойно можно вставлять любые символы без проблем. Я считаю, что закодированные символы это как раз признак некрасивого кода.
В общем, довольно посредственный списочек, хотя для новичков вполне сойдёт, с опытом потом придёт понимание.
Кстати, у самого Криса Койера код пока не соответствует его же собственным рекомендациям.
Если я такое говорил (не помню уже, что именно я говорил тебе по этому поводу), то я имел в виду, что в верстке, которая делается на заказ, еще не время его применять. Но на своих сайтах я HTML5 использую смело.
Видимо, это утверждение основано на высокой популярности jQuery и легкости его освоения и применения.
Если ты укажешь относительный путь к изображению, то твои читатели в RSS его не увидят. Что тут непонятно?
Повторяю, какая связь HTML и RSS? Он RSS готовит парсингом HTML-страничек, что ли? :) Умная CMS должна сама пребразовать URL с относительным путём для RSS. Правда, я не знаю, бывают ли такие.
Прямая. Какой адрес изображения указан при создании записи, точно такой адрес и уходит в RSS.
Вот именно. Потому и написан этот пункт о путях.
Это из-за кэширования, которое стоит на блоге. Без него сайт тормозит =(
У тебя комменты на модерацию уходят, если URL написать.
О, блин. Вообще не уходят уже никакие.
И предупреждения никакого. Очень плохо.
извините, но я не вижу в чем «красивость» этого кода. К примеру где H1 документа? при этом не все браузеры поддерживают HTML5, а утверждение что HTML5 лучший ошибочно, по крайней мере на данный момент. Возможно ЭТО кому то и покажется красивым, но только не для поисковиков…
Ну ты невнимательный.
И еще. Поисковикам, которые имеют значение — нравится. Проверено на собственном опыте