Поиск дубликатов на доске доске объявлений
Статья будет полезна тем, кто имеет или планирует создать доску объявлений, даже если речь идет о небольшом городском портале.
Основная проблема сервисов бесплатных объявлений, как для его пользователей, так и для администрации, это спам дублями в каталоге. Большинство людей думают, что если добавлять одинаковые объявления чуть ли не каждый день, то от этого будет больше толку. Проблема для модератора в том, что при большом потоке отфильтровать в ручном режиме практически невозможно, необходимо подключать автоматизированное решение. В итоге если с этим не бороться, то каталог постепенно заспамится однотипными предложениями и что-то найти в нем будет очень затруднительно, в худшем случае сервис может попасть под фильтры поисковых систем.
Решение и алгоритм поиска дубликатов объявлений
Необходимо внедрить решение (программную доработку), которое будет позволять находить нечеткие дубликаты и предлагать модератору выбор – удалить или оставить объявление. Данное решение используется на живой доске бесплатных объявлений http://maxni.ru/. Ради опыта, можете попробовать добавить два дубликата или более и через несколько часов, можете быть уверены, что дубликаты будут удалены.
Индексируем тексты
- Каждую публикацию необходимо обработать: убрать все html теги, числа и другую мало полезную информацию. Формируем массив из слов.
- Исключаем фразы, что меньше 4 знаков, отбираем 15 самых длинных фраз.
- Для каждой фразы производим расчет контрольной суммы и записываем в БД. Можно использовать crc32, формат записи: «id суммы», «id док-та» и сама «сумма».
- В отдельную таблицу БД необходимо записать параметры текста: «md5», «количество слов».
- Для текстов, где не нашлось 15 длинных фраз, необходимо в БД второе поле, куда и будем их записывать (длинна док-та в словах).
Ниже показан пример таблиц в базе данных, где хранятся записи про дубликаты:
CREATE TABLE `items_hashes` (
`id` int(11) NOT NULL auto_increment,
`doc_id` int(11) NOT NULL,
`word_hash` int(11) NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `items_hashes_summary` (
`doc_id` int(11) NOT NULL,
`full_hash` char(32) NOT NULL,
`length` smallint(11) NOT NULL,
PRIMARY KEY (`doc_id`)
);
Находим дубликат
После того, как все тексты объявлений находятся в базе данных, мы можем выполнить проверку на уникальность с новым добавленным объявлением:
- Используя записи в таблице «items_hashes_summary», мы сопоставляем на полное совпадение, если мы получаем данное совпадение, то это дубликат – 100% и дальнейшие процедуры не требуются.
- Если совпадения в п.1 не было, тогда необходимо сделать, что писалось выше в п. 1-3 (индексация текста), без записи в БД.
- Необходимо выполнить поиск на совпадающие фразы и посчитать количество совпадений (ниже написано как).
- Далее считаем в процентном соотношении совпадения с каждым док-ом:
$similarity = ($intersecs/$length)*100, где $length — длинна самого короткого из сравниваемых док-ов; $intersecs — количество совпавших фраз.
Поиск на совпадающие фразы:
SELECT doc_id, COUNT(id) as intersects FROM items_hashes
WHERE (word_hash = %cur_doc_hash1% OR word_hash = %cur_doc_hash2% OR ... )
GROUP BY doc_id
HAVING intersects > 1 (если объем коллекций большой, то лучше указать не менее 5, чтобы избежать длительной обработки)
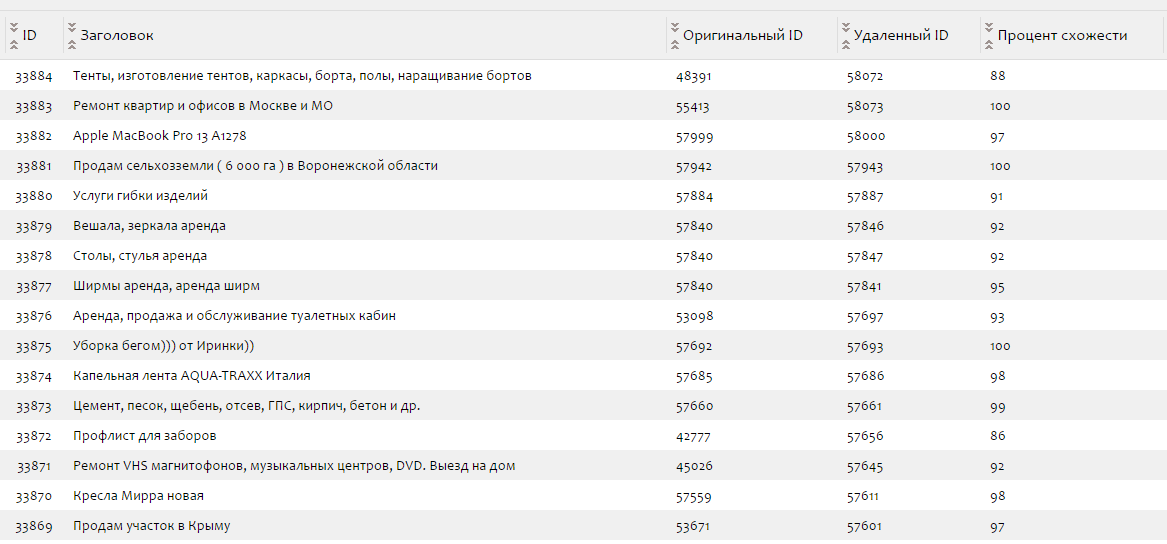
Как показывает практика, что дубликат определяется на 80%, в целом можете сами провести эксперименты, при каких значениях у вас будет лучший результат.
Удалять автоматом или нет?
Лучше использовать полу ручной режим, т.к. удаление в автоматическом режиме может быть чревато негативными последствиями, дело в том, что пользователь может добавлять разные товары, но практически с одинаковым текстом, пример:
- Система реализует Б/у металлоформы свай С140.35 в хорошем рабочем состоянии. Подробности по телефону или заявке.
- Система реализует Б/у металлоформы свай С90.30 в хорошем рабочем состоянии. Подробности по телефону или заявке.

Как видно, различия в маркировке свай и это разный товар, но система определяет это дубликатом, т.к. совпадение на 90%. Однако по своей сути, это разные объявления и будет плохо, если пользователь старался и добавлял публикации, а система их автоматически потрет. Как раз в таких ситуациях и нужен человеческий фактор, чтобы понять, это действительный дубликат или все же разные объявления.
Можно ли обойти систему?
Да, систему можно обойти, для этого необходимо составить полностью разные и уникальные объявления. Однако пользователи редко это делают, большинство считает, что переставив фразы и предложения местами, этого будет достаточно, а на деле нет :)
Также дополнительно можно делать проверку на одинаковые ФИО, телефон, email и ключевые фразы, которые содержит объявление и дополнительно фильтровать такие публикации.